Разметка корпуса
Цель разметки состоит в получении корпуса примеров отзывов с выделенными и размеченными именованными сущностями, отражающими фармакотерапевтическую помощь и семантически разметить характеристику лекарственного препарата. Таким образом, корпус был размечен для создания атрибутов лекарственных препаратов, заболеваний (в том числе их симптомов) и нежелательных побочных реакций от определенного препарата. Мы определили набор интересующих нас именованных сущностей и разметили их вручную. Выбранные сущности и их описание представлены ниже.
Medication
Сущность включает в себя всё, что связано с упоминаниями лекарственных препаратов и их производителей. Теги этой сущности указаны далее в таблице.
| Drugname | Отмечает упоминание о препарате. Например, в предложении «Препарат Aventis “Трентал” для улучшения мозгового кровообращения» слово “Trental” (без кавычек) помечено как Drugname. |
| DrugBrand | Название препарата также помечается как DrugBrand, если оно является зарегистрированным товарным знаком. Например, в предложении «Противовирусный и иммунотропный препарат Экофарм “Протефлазид”» слово “Протефлазид” помечено как DrugBrand. |
| Drugform | Лекарственная форма препарата (мазь, таблетки, капли и т.д.). Например, в предложении «Эти таблетки не плохие, если начать принимать с первых признаков застуды» “таблетки” помечено как DrugForm. |
| Drugclass | Тип препарата (седативное, противовирусное средство, снотворное и т.д.) Например, в предложении «Противовирусный и иммунотропный препарат Экофарм “Протефлазид”» (The Ecopharm “Proteflazid” antiviral and immunotropic drug) два слова получат тэг Drugclass - “Противовирусный” и “иммунотропный”. |
| MedMaker | Производитель лекарств. Эта сущность имеет две характеристики: Domestic (отечественный) и Foreign(зарубежный). Например, в предложении «Седативный препарат Материа медика “Тенотен”» комбинация слов “Материа медика” помечается как MedMaker/Domestic. |
| MedFrom | Это аттрибутсущности Medication, который принимает два значения – Domestic(отечественный) and Foreign(зарубежный), характеризующие производителя лекарства. Например, в предложении «Седативные таблетки Фармстандарт “Афобазол”» название препарата “Афобазол” имеет атрибут MedFrom равный Domestic. |
| Frequency | The drug usage frequency. For example, in the sentence «Неудобство было в том, что его приходилось наносить 2 раза в день» (Its inconvenience was that it had to be applied two times a day), the phrase “2 раза в день” (two times a day) is marked as Frequency. |
| Dosage | Дозировка препарата (включая единицы измерения, если указано). Например, в предложении «Ректальные суппозитории “Виферон” 15000 МЕ – эффекта ноль» сущность “15000 МЕ” помечается как Dosage. |
| Duration | Этот тэг указывает продолжительность использования. Например, в предложении «Время использования: 6 лет» , “6 лет” помечено как Duration. |
| Route | Способ применения (как применять препарат). Например, в предложении «удобно то, что можно готовить раствор небольшими порциями» комбинация слов “можно готовить раствор небольшими порциями” помечается как сущность с тэгом Route. |
| SourceInfodrug | Источник информации о препарате. Например, в предложении «Этот спрей мне посоветовали в аптеке в его состав входят такие составляющие вещества как мята» комбинация “посоветовали в аптеке” помечается как SourceInfoDrug. |
Disease
Данная сущность связана с заболеваниями или симптомами. Указывает на причину приёма препарата, название заболевания и улучшение или ухудшение состояния пациента после приема препарата. Теги этой сущности указаны далее в таблице.
| Diseasename | Наименование заболевания. Если автор отзыва упоминает название заболевания, от которого он принимает лекарство, оно помечается как Diseasename. Например, в предложении «у меня вчера была диарея», слово “диарея” будет размечено как Diseasename. Если в одном предложении есть два или более упоминаний о болезнях, они размечаются отдельно. В предложении «Обычно весной у меня сезон аллергии на пыльцу и депрессию», оба слова “аллергия” и “депрессия” размечаются как Diseasename. |
| Indication | Показания к применению (симптомы). В предложении «У меня постоянный стресс на работе», слово “стресс” размечается как Indication. Также, в предложении «Я принимаю витамин С для профилактики гриппа и простуды», сущность “для профилактики” тоже размечается как Indication. В другом примере, в предложении «У меня температура 39.5» (I have a temperature of 39,5) слова “температура 39.5” размечаются как Indication. |
| BNE-Pos | Эта сущность указывает на положительную динамику после или во время приема препарата. В предложении «препарат Тонзилгон Н действительно помогает при ангине», слово “помогает” размечается как BNE-Pos. |
| ADE-Neg | Негативная динамика после начала или какого-то периода использования препарата. Например, в предложении «Я очень нервничаю, купила пачку “персен”, в капсулах, он не помог, а по моему наоборот всё усугубил, начала сильнее плакать и расстраиваться», слова “по моему наоборот всё усугубил, начала сильнее плакать и расстраиваться” размечаются как ADE-Neg. |
| NegatedADE | Эта сущность указывает на то, что препарат не действует после пропитого курса. Нпример, в предложении «…боль в горле притупляют, но не лечат, временный эффект, хотя цена великовата для 18-ти таблеток» слова “не лечат, временный эффект” рамечаются как NegatedADE. |
| Worse | Ухудшение состояния после приема препарата. Например, в предложении «Распыляла его в нос течении четырех дней, результата на меня не какого не оказал, слизистая еще больше раздражалось», слова “слизистая еще больше раздражалось” размечаются как Worse. |
ADR
Неблагоприятные побочные эффекты упомянутые в тексте. Например: «После недели приема Кортексина у ребенка начались судороги». В этом предложении слово “судороги” размечается как сущность ADR.
Note
Мы используем эту сущность, когда автор дает рекомендации, советы и т.д., но не указывается явно, помогает ли препарат или нет. К этой сущности относятся такие фразы, как “Я не советую”. Например, фраза «Нет поддержки для иммунной системы» размечается сущностью Заметка.
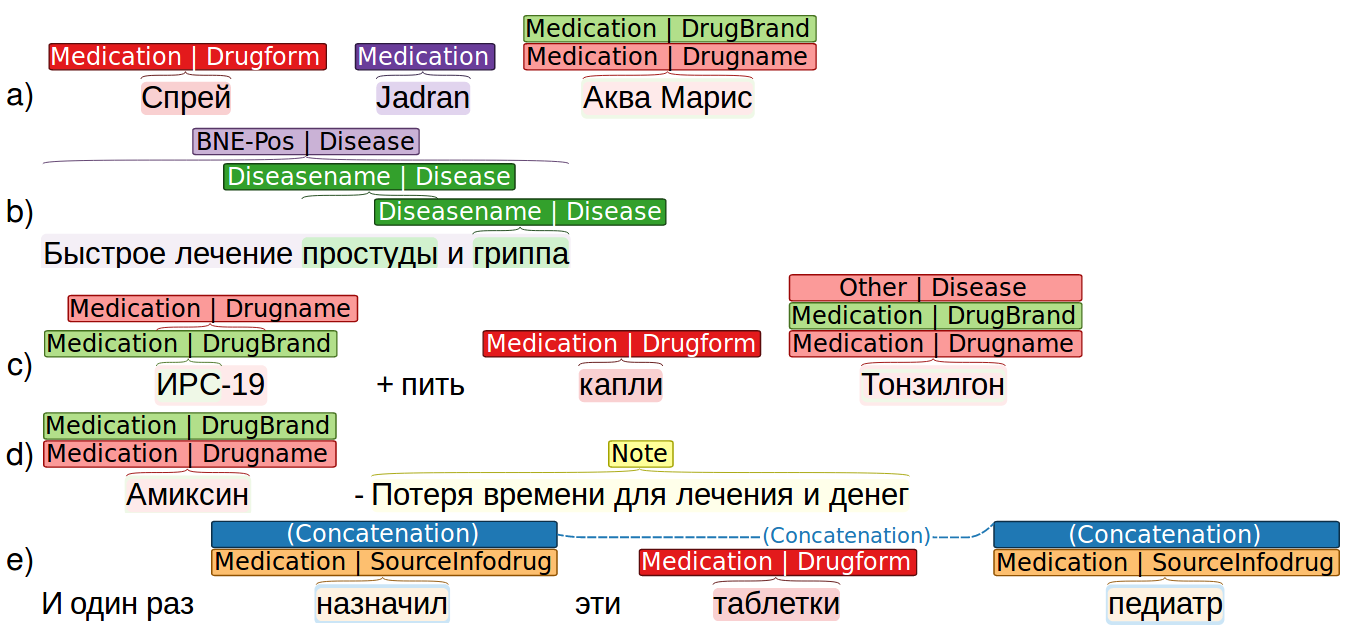
Рисунок 1. Пример разметки.
В начале процесса разметки мы встретились с несколькии повторяющимися ситуациями, в которых нужно было разобраться:
-
Простая разметка, где сущность состоит из 1-3 слов и для его разметки используется один тег. Аннотаторы должны выбрать текст, состоящий из минимального количества значащих слов, исключая союзы, вводные слова и знаки препинания.
-
Прерывистые сущности - сущности, разделенные словами, которые не являются частью рассматриваемой сущности. Нужно выбрать части сущности и соединить их. В таких случаях мы используем связь “объединение”. В примере (д) на рисунке 1 слова “назначил” и “педиатр” помечены как объединённые сущности типа “sourceInfoDrug”.
- Пересечение разметки. Сущность отражает комбинацию нескольких разнородных значений. В этом случае используются несколько разных тегов. Например, в предложении “Быстрое лечение простуды и гриппа” (см. рисунок 1, пример (б)), слова “простуда” and “гриппа” принадлежат сущности “diseasename”, но вся фраза является сущностью типа “BNE-Pos”. Если сущность имеет несколько тегов одновременно (например, “drugname” и “drugbrand”), все они должны быть помечены как сущность “Aqua Maris” в предложении “Спрей Jadran Aqua Maris” (см. рисунок 1, пример (а)).
- Другая сложная ситуация - когда в тексте упоминается аналог рассматриваемого лекарства (в некоторых случаях несколько), например, когда пользователь написал об одном лекарстве и описал альтернативный, который ему помог. В этом случае применяется тег “Other” (пример (в)).
Зачастую встречаются и субъективные аргументы автора. Мы размечаем такие высказывания тэгом “Note”. Например, “странное лекарство”, “не впечатлило”, “не понятно действует или нет”, “неоднозначный эффект” (пример (d) на рисунке 1). Кроме этого, этот тег предназначен для случаев неоднозначных высказываний пользователя, т.е. когда невозможно однозначно определить тег.
Нормализация
В нашем исследовании, под нормализацией мы понимаем сопоставление информации, встречающейся в тексте с информацией представленной во внешних официальных реестрах и классификаторах. Для русского языка среди таких внешних источников имеются:
- Международная классификация болезней (МКБ-10 или ICD-10) – это международная система классификации болезней, которая содержит в себе 22 класса медицинских диагнозов, каждый из которых может включать до 100 категорий. МКБ позволяет сводить словесные формулировки диагнозов болезней и проблем, связанных со здоровьем, к унифицированным кодам.
- Анатомо-терапевтически-химическая система классификации (АТХ или англоязычная аббревиатура “АТС”) – это международная система классификации лекарственных средств содержащая 14 групп лекарственных препаратов и 4 уровня подгрупп. МКБ-10 и АТХ имеют иерархическую структуру листьями (конечными элементами) которой могут быть конкретные заболевания или препараты, а узлами — группы или категории. Каждый узел имеет код, включающий в себя код родительского узла.
- Государственный реестр лекарственных средств (ГРЛС)\cite{SRD} – реестр содержащий в себе подробную информацию о лекарственных препаратах, зарегистрированных в РФ. Включая возможных производителей, дозировки, лекарственные формы, коды АТХ, показания к применению и прочее.
- MESHRUS переведённый на русский вариант базы Medical Subject Headings (MESH). База MESH содержит понятия извлечённые из научных журнальных статей и книг и создана для их индексации и поиска. Наполнение базы MESH происходит с использованием статей на английском языке, однако существуют переводы базы на разные языки. Мы использовали русский вариант — MESHRUS, она является менее полным аналогом англоязычного варианта, например не содержит определений понятий.
Среди международных систем стандартизации понятий наиболее полным и большим метотезаурусом является UMLS, который объединяет в себе большинство баз медицинских понятий и наблюдений, в том числе MESH (MESHRUS), ATC, ICD-10. Все уникальные понятия (концепты) в UMLS имеют идентифицирующий код CUI. По этому CUI можно получить информацию о концепте, которая содержится во всех базах. Из всех баз внутри UMLS, только MESHRUS содержит русский язык. База MESH является словарём, предназначенным для индексации биомедицинской информации. Что делает её крайне полезной при анализе медицинских статей.
Нормализация основанная на классификаторах АТХ и МКБ-10.
Нормализация проводилась вручную силами аннотаторов. Для этого мы применили процедуру, включающую следующие шаги: автоматическая группировка понятий (стандартизация), ручная проверка групп понятий, сопоставление групп понятий с терминами баз АТХ и МКБ-10. Автоматическая группировка понятий проводится с использованием близости, рассчитанной алгоритмом Ратклиффа\Обершелла, который основан на поиске максимальных совпадающих подстрок для пары строк. Анализируя множество сущностей, каждая новая сущность добавляется в одну из существующих групп G, если средняя близость со всеми сущностями этой группы больше 0.8 (подобрано эмпирически), иначе создается новая группа. Множество G изначально пустое и первая сущность сразу создаёт группу с единственной сущностью. Для обозначения каждой группы выбирается понятие, которое наиболее часто встречается в корпусе. Далее полученное множества групп проверяется и дорабатывается аннотатарами для создания более крупных групп или для изменения их названий.
После этого, полученные названия групп понятий, отмеченные тегами Diseasename, Drugname и Drugclass, вручную сопоставлялись с терминами АТХ и МКБ-10 и получали коды соответствующих терминов из классификаторов. По итогам этой процедуры для сущностей типа Diseasename было сопоставлено 140 уникальных кодов из МКБ-10, упоминаемых 1333 раза в корпусе, а для сущностей типа Drugname сопоставлен 171 уникальный код АТХ с суммарным количеством упоминаний равным 2325. 26 кодов АТХ было назначено сущностям из Drugclass, упомянутым 1092 раза. Некоторые сущности Drugclass не имели соответвующего кода (например “гомеопатия”), кроме того, некоторые коды объединяли в себе несколько классов, которые авторы отзывов часто разделяют (например снотворные и седативные препараты).
Нормализация, базирующуяся на концептах из MESHRUS
MESHRUS содержит множество русскоязычных понятий и соответствующие им CUI коды из метатезауруса UMLS. Концепты могут состоять из слова или последовательности слов. Мы использовали 2 подхода для автоматического поиска и сопоставления понятий из MESHRUS со словами в корпусе. Следующие типы предобработки были проведены для сопоставления слов из корпуса с понятиями из словаря: лемматизация слов, приведение к одному регистру, фильтрация по длине, частоте и частям речи.
два подхода тут с формулами
В разделе Статистика продемонстрированы результаты нормализации. Колонка “MESHRUS - total” содержит число слов из W, которые пересекались с сущностями данного подкласса, а “MESHRUS - unique” показывает количество уникальных кодов, которые попадали под сущности данного подкласса.