Corpus shot summary
We present the first Russian annotated corpus of medicine reviews by Internet users, along with a complex of deep learning neuron nets for the extraction of pharmacologically meaningful entities from Russian texts.
Its basis were 1660 reviews from a medical forum called OTZOVIK (OTZOVIK - Internet forum from which user reviews were taken http://otzovik.com, which is dedicated to consumer reviews on medications. On that website there is a partition where users submit posts by filling special survey forms. The site offers two forms: simplified and extended, the latter being optional. In this form a user selects a drug name and fills out the information about the drug, such as: adverse effects experienced, comments, positive and negative sides, satisfaction rate, and whether they would recommend the medicine to friends. In addition, the extended form contains prices, frequency, scores on a 5-point scale for such parameters as quality, packing, safety, availability. A sample post for “Глицин” (Glycine) is shown in Table “Review example”.
We used information only from the simplified form, since the users had rarely filled extended forms in their reviews. We considered only the fields Heading, General impression and Comment. Furthermore, some of the reviews are written in common language and do not follow formal grammar and punctuation rules. The consumers described not only their personal experience, but sometimes opinions of their family members, friends or others. The main specifications of our corpus are shown in sections Statistics.
In future work, we plan to expand the corpus by adding information from the form fields: Advantages, Disadvantages, Overall assessment and Recommendation to friends for the task of analyzing the tonality of a response, etc.
Review example
| Overall impression | “Помог чересчур!” (Too much help!) |
| Advantages | “Цена” (Price) |
| Disadvantages | “отрицательно действует на работоспособность” (It has a negative effect on productivity) |
| Would you recommend it to friends? | “Нет” (No) |
| Comments | “Начала пить недавно. Прочитала отзывы вроде все хорошо отзывались. Стала спокойной даже чересчур, на работе стала тупить, коллеги сказали что я какая то заторможенная, все время клонит в сон. Буду бросать пить эти таблетки.” (I started taking recently. I read the reviews, and they all seemed positive. I became calm, even too calm, I started to blunt at work, сolleagues said that I somewhat slowed down, feel sleepy all the time. I will stop taking these pills.) |
The corpus annotation includes mentions of the following entities: Medication (17779 mentions), Adverse Drug Reaction (844), Disease (9285), and Note (2319). Two of them – Medication and Disease – comprise a set of attributes. The neural network complex is calibrated on CADEC texts by numerical comparison to up-to-date literature results, and adapted to Russian language texts, which makes it appropriate to estimate the current accuracy baseline of the problem for Russian texts. The influence of choice of different word vector representations of Russian language models, text normalization procedures, and other preliminary processing, is evaluated to obtain their more efficient combination with the selected neuronet models. As a result, a state-of-the-art level of accuracy for the pharmacological entity extraction problem for Russian is estimated, which matches the accuracy levels for an analogous task for other languages.
Tags description
-
Medication This entity includes everything related to the mentions of drugs and drugs manufacturers. Selecting a mention of such entity, an annotator had to specify an attribute out of those specified in section Annotation, thereby annotating it, for instance, as a mention of the attribute “DrugName” of the entity “Medication”.
-
Disease This entity is associated with diseases or symptoms. It indicates the reason for taking a medicine, the name of the disease, and improvement or worsening of the patient state after taking the drug. Attributes of this entity are specified in Annotation.
-
ADR This entity is associated with adverse drug reactions in the text. For example, one post said: «После недели приема Кортексина у ребенка начались судороги» (After a week of taking Cortexin, the child began to cramp). In this sentence, the word “удороги” (“cramp”) is labeled as an ADR entity.
-
Note We use this entity when the author makes recommendations, tips, and so on, but does not explicitly state whether the drug helps or not. These include phrases like “I do not advise”. For instance, the phrase “Нет поддержки для иммунной системы” (No support for the immune system) is annotated as a Note.
The corpus contains consumer posts on 384 drugs, mentioned 2360 times. These drugs relate to 36 drug classes according to the classification from the State Register of Drugs GRLS.
The most popular drug classes mentioned in corpus are antiviral (74 drugs) and sedative (39 drugs). The sums of entries of these drugs have parts from all drug name attribute entries equal to 48.52% and 17.07% correspondingly. The proportions of entry counts of the most popular drugs to the total number of entries of antiviral drugs are: “Виферон” (Viferon) (6.9%), “Ингаверин” (Ingavirin) (5.41%) and “Ацикловир” (Acyclovir) (4.54%). For the sedative drugs, these are: “Глицин” (Glycine) (16.38%), “Валериана” (Valeriana) (14.39) “Афобазол” (Afobazol) (8.93%).
This corpus is used further to get a baseline accuracy estimate for the named entity recognition task.
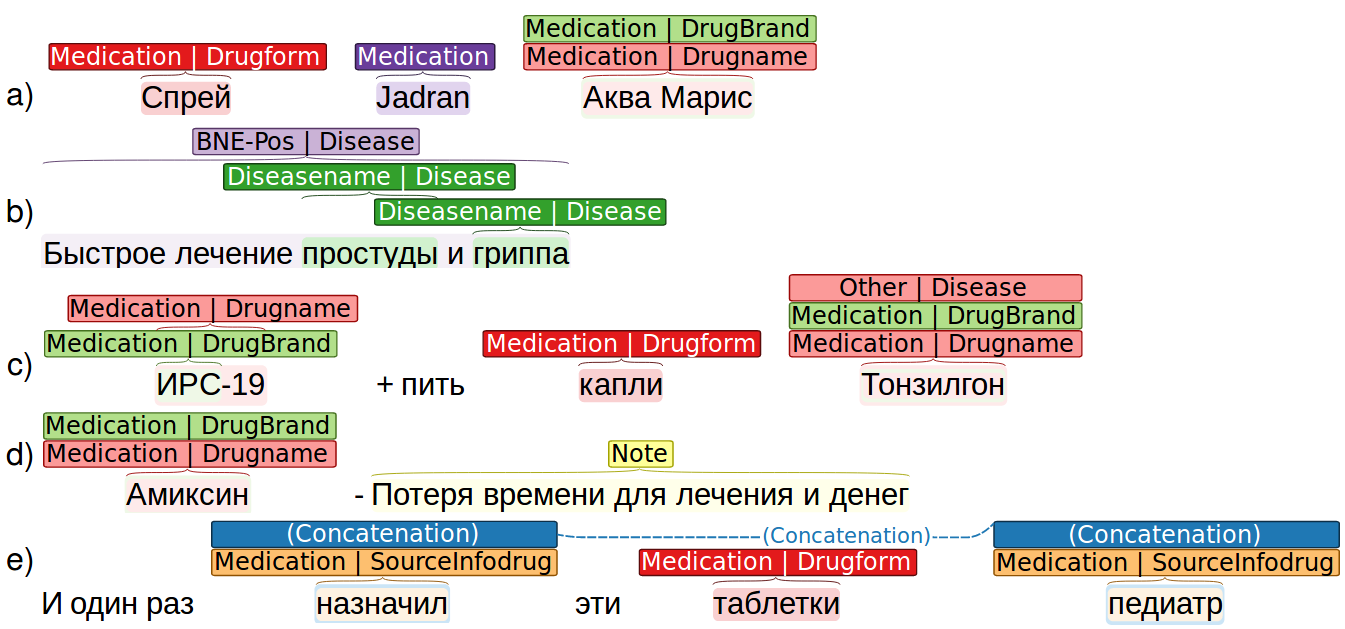
Fig 1. Review example.